所有代码使用iPython Notebook实现
目录
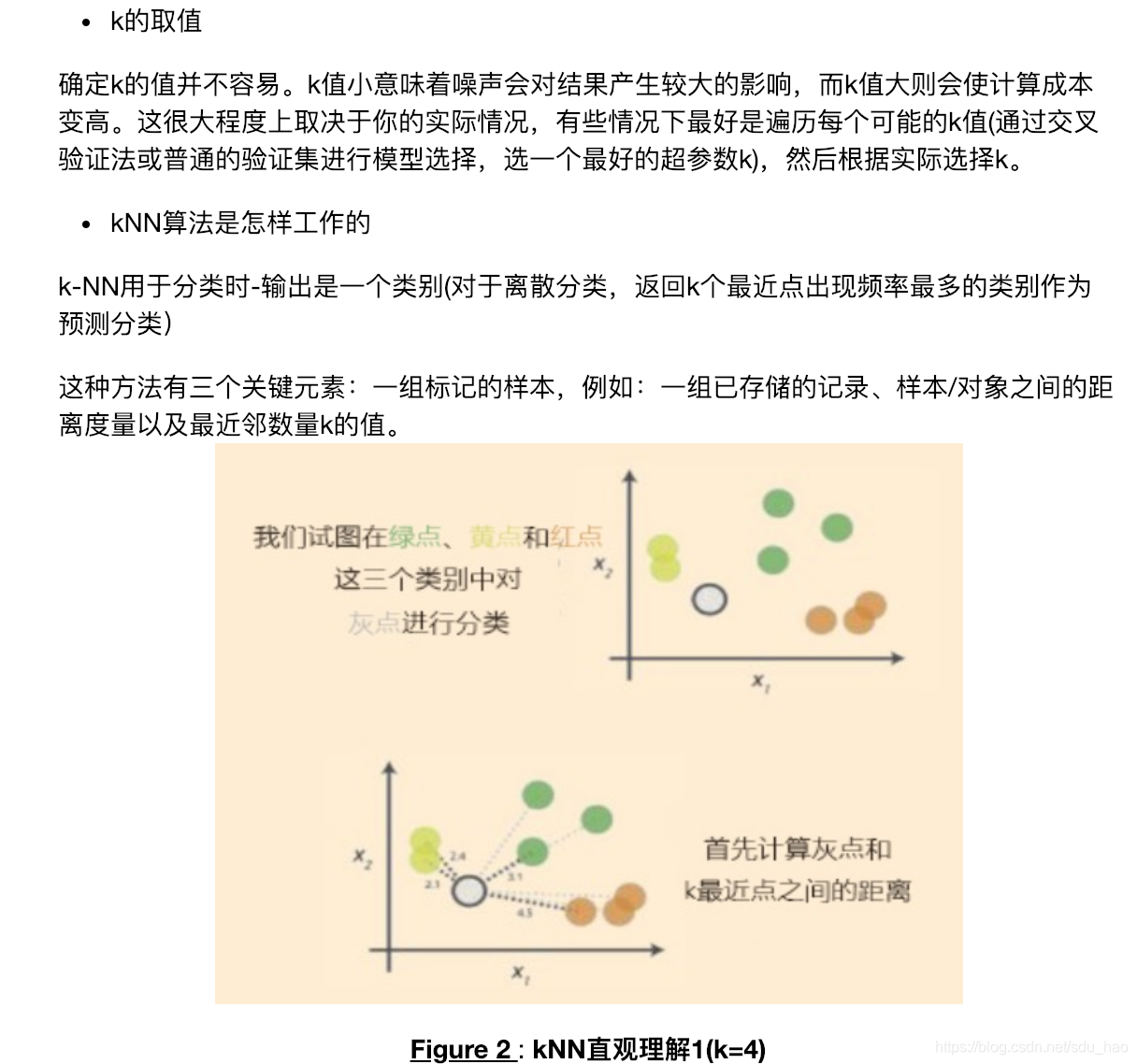
实验综述
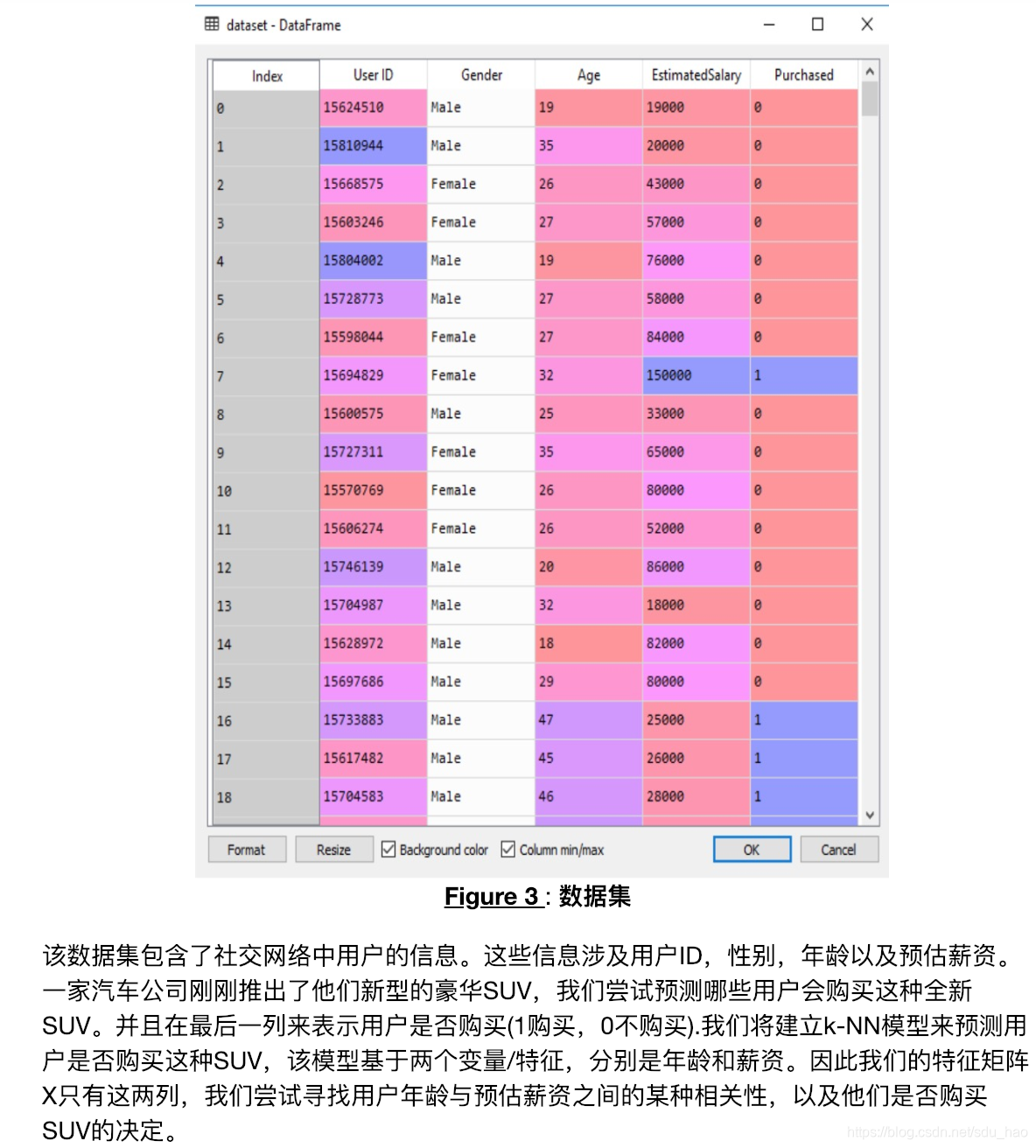
数据集
1.数据预处理
-
-
-
-
import matplotlib.pyplot as plt
-
-
-
-
data = pd.read_csv('Social_Network_Ads.csv')
-
-
-
X = data.iloc[:,2:-1].values
-
Y = data.iloc[:,-1].values
-
-
-
-
-
-
-
-
-
-
-
-
from sklearn.model_selection import train_test_split
-
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.25,random_state=0)
-
-
-
from sklearn.preprocessing import StandardScaler
-
-
-
-
X_train = sc.fit_transform(X_train)
-
X_test = sc.fit_transform(X_test)
2.使用k-NN对训练集进行训练
-
-
from sklearn.neighbors import KNeighborsClassifier
-
-
classifier = KNeighborsClassifier(n_neighbors = 5,metric='minkowski',p=2)
-
-
classifier = classifier.fit(X_train,Y_train)
3.对测试集进行预测
-
-
y_pred = classifier.predict(X_test)
4.生成混淆矩阵
-
-
from sklearn.metrics import confusion_matrix
-
-
cm = confusion_matrix(Y_test,y_pred)
-
-
-
num_correct = np.sum(Y_test==y_pred)
-
accuracy = float(num_correct)/len(y_pred)
-






没有评论:
发表评论